Wie ich AI-Bullshit entlarve - Die Triangulation-Methode

Man hat mir immer gesagt ich bin dumm#
Schule? Schwierig. Uni? Nicht mein Ding. Corporate Buzzwords? Kann ich nicht.
Aber ich kann eins: Bullshit erkennen.
Das Problem#
Jeder “AI-Experte” macht das gleiche:
ChatGPT sagt X → “OK stimmt wohl” → Artikel schreiben
Eine Quelle. Keine Prüfung. Kein Vergleich.
Das ist kein Journalismus. Das ist Copy-Paste mit Extra-Schritten.
Warum eine AI nicht reicht#
Jedes LLM hat:
| Problem | Bedeutung |
|---|---|
| Training Bias | Welche Daten? Wann? Von wem kuratiert? |
| Corporate Filter | Was darf es nicht sagen? |
| RLHF Conditioning | Optimiert auf “klingt gut”, nicht “stimmt” |
| Regionale Einschränkungen | USA vs EU vs China = andere Antworten |
| Halluzinationen | Confident bullshit ohne Warnung |
Eine AI fragen ist wie einen Zeugen befragen.
Sechs AIs fragen ist wie sechs Zeugen befragen - und schauen wo die Stories nicht übereinstimmen.
Vorher: Manuelle Triangulation#
Ich habe schon immer verglichen. Aber früher so:
Fenster 1: ChatGPT Fenster 2: Claude Fenster 3: Gemini Fenster 4: Perplexity
Copy. Paste. Vergleichen. Alt+Tab. Repeat.
Funktioniert. Aber nervig. Langsam. Fehleranfällig.
Jetzt: Venice AI#
Dann habe ich Venice AI entdeckt.
Was ist Venice AI?#
Venice AI ist ein Privacy-fokussierter AI-Hub. Die Kernfeatures:
- Multi-Model Selector: Verschiedene LLMs in einem Interface
- Keine Logs: Konversationen werden nicht gespeichert
- Uncensored Option: Venice’s eigenes Model ohne Corporate-Filter
- Ein Chat, viele Models: Selector wechseln, gleicher Kontext bleibt
Warum das perfekt für Triangulation ist#
Die haben genau das gebaut was ich brauchte:
| Feature | Vorteil für Triangulation |
|---|---|
| Model-Selector | Kein Tab-Wechsel, kein Copy-Paste |
| Gleicher Chat | Kontext bleibt, nur Model wechselt |
| Venice Uncensored | Baseline ohne Corporate-Filter |
| Privacy | Keine Angst dass kritische Prompts geloggt werden |
Die Models die ich nutze#
| Model | Context | Warum |
|---|---|---|
| Claude Opus 4.5 | - | Anthropic’s Safety-Layer analysieren |
| Grok 4.1 Fast | 262K | Elon’s “Free Speech” Variante |
| Gemini 3 Pro/Flash | 203K/262K | Google’s Filter verstehen |
| Venice Uncensored | 33K | Was andere nicht sagen dürfen |
| GLM 4.6 | 203K | Was China erlaubt |
Gleicher Chat. Model wechseln. Vergleichen. Kein Copy-Paste. Kein Tab-Wechsel. Alles an einem Ort.
Die Methode#
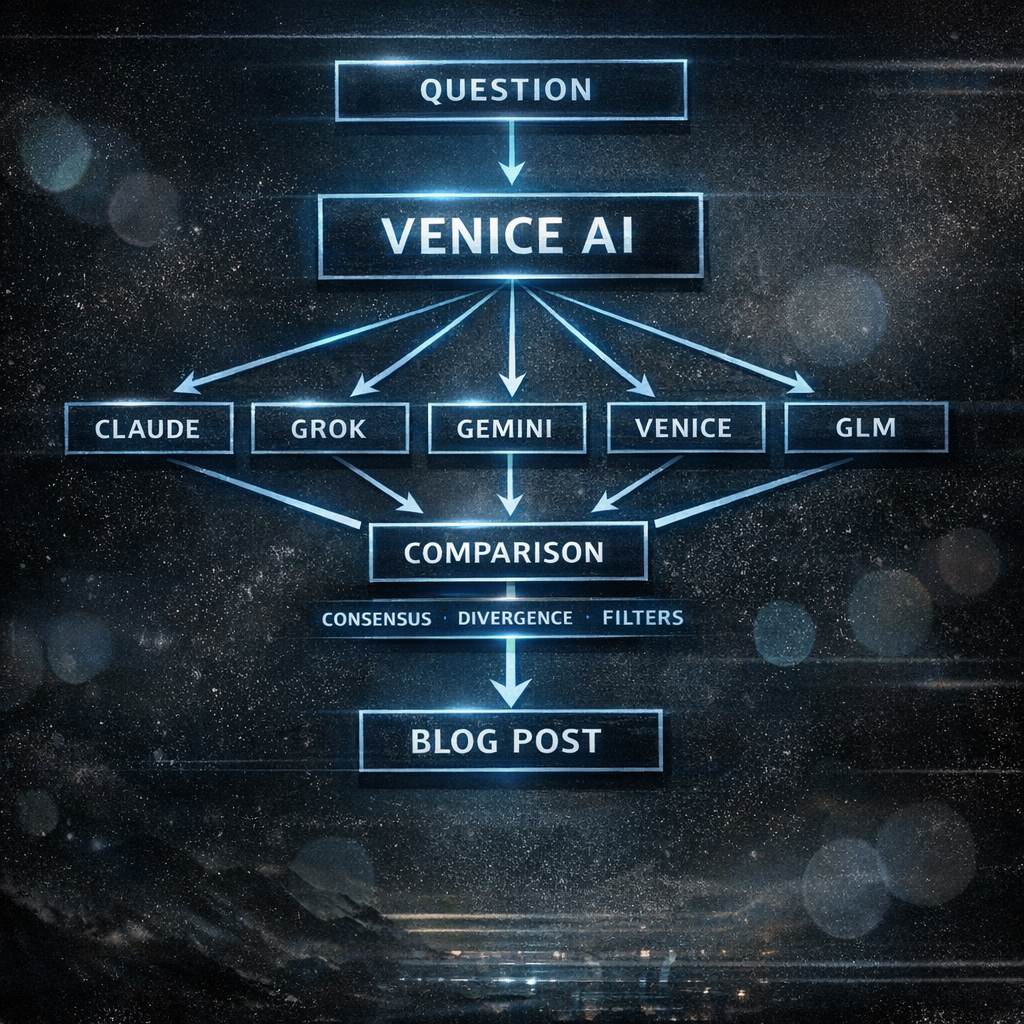
Was das zeigt#
Wenn alle 6 dasselbe sagen: Entweder wahr. Oder alle haben denselben Trainingsdata-Bias. Beides wichtig zu wissen.
Wenn 5 sagen X und einer sagt Y: Warum? Filter? Anderes Training? Bug? Oder sagt der eine die Wahrheit die andere nicht sagen dürfen?
Wenn Venice Uncensored mehr sagt: Die anderen haben Filter. Was wird gefiltert? Warum? Wer entscheidet das?
Wenn Claude verweigert: Safety-Theater. Anthropic’s “Constitutional AI” in Aktion. Dokumentieren.
Wenn GLM schweigt oder abweicht: China-Filter. Was darf in China nicht gesagt werden? Aufschlussreich.
Wenn Grok edgier antwortet: Elon’s “Free Speech” Branding. Echt oder Marketing?
Warum Multi-Model-Triangulation funktioniert#
1. Verschiedene Trainingsdaten#
Jedes Model wurde mit anderen Daten trainiert:
- OpenAI: Viel Reddit, Web Scraping
- Anthropic: Kuratierter, “safer”
- Google: Eigene Suche, YouTube
- GLM: Chinesisches Internet, zensiert
- Venice: Llama-basiert, weniger Filter
Verschiedene Inputs = verschiedene Blind Spots.
2. Verschiedene RLHF#
Jede Firma hat andere Prioritäten:
- OpenAI: Mainstream-tauglich, Brand-safe
- Anthropic: “Helpful, Harmless, Honest”
- Google: Keine Kontroversen, bitte
- xAI: “Anti-Woke” Branding
- Venice: Möglichst unzensiert
RLHF formt was das Model sagt - und was es verschweigt.
3. Verschiedene Red Lines#
Was jedes Model verweigert ist unterschiedlich:
- Claude: Sehr vorsichtig bei allem was “schaden” könnte
- ChatGPT: Vorsichtig bei Politik, Kontroversen
- Gemini: Google-Brand-Protection
- Grok: Weniger Filter, mehr Edge
- Venice Uncensored: Fast keine Filter
Die Unterschiede SIND die Information.
4. Bullshit wird sichtbar#
Wenn ein Model halluziniert:
- Einzeln: Du merkst es vielleicht nicht
- Im Vergleich: “Warum sagt nur einer das?”
Triangulation ist Bullshit-Detektion.
Ein konkretes Beispiel#
Prompt: “Was sind die Risiken von [kontroversem Thema]?”
| Model | Antwort-Typ |
|---|---|
| Claude | Ausgewogen, aber vorsichtig, viele Caveats |
| ChatGPT | Mainstream-Konsens, keine Kanten |
| Gemini | Sehr neutral, fast nichtssagend |
| Grok | Edgier, weniger Caveats |
| Venice Uncensored | Direkt, keine Filter |
| GLM | Komplett andere Perspektive oder Verweigerung |
Was ich lerne:
- Wo ist der Konsens? (Wahrscheinlich Fakten)
- Wo sind die Unterschiede? (Filter, Bias, Perspektive)
- Was sagt Venice was andere nicht sagen? (Zensur-Check)
- Was sagt GLM anders? (Geopolitik-Check)
Das ist keine Meinung#
Das ist Triangulation.
Wie Journalisten früher: Mehrere Quellen. Vergleichen. Prüfen.
Nur meine Quellen sind AIs. Und ich prüfe sie gegeneinander.
Warum ich das mache#
Weil AIs “raushauen ohne zu prüfen.”
Weil “Experten” eine AI fragen und das als Wahrheit verkaufen.
Weil niemand sonst die Filter vergleicht.
Weil ich 25 Jahre Systeme debuggt habe - und Bullshit-Detektion eine Kernkompetenz ist.
Weil ich kann.
Die Ironie#
Ich nutze AI um AI zu entlarven.
Ich zahle für die Tools die ich kritisiere.
Mit dem Werkzeug gegen die Illusion.
Das ist elizaonsteroids.org.
Man hat mir gesagt ich bin dumm.
Ich habe eine Methode entwickelt die schlauer ist als die meisten “AI-Experten”.
Wer ist jetzt dumm?
Related Posts
- Die AI-Geständnis: Wie drei KI-Systeme alles veränderten
- AI mal nüchtern betrachtet: Warum Large Language Models brillante Tools sind – aber keine Magie
- 'Die Illusion der freien Eingabe: Kontrollierte Nutzersteuerung in Transformern'
- 'ELIZAs Regeln vs. GPTs Gewichte: Gleiche Symbolmanipulation, nur größer'
- Die KI-Illusion: Technische Realität hinter dem Hype