How I Expose AI Bullshit - The Triangulation Method

I’ve Always Been Told I’m Stupid#
School? Difficult. University? Not my thing. Corporate buzzwords? Can’t do them.
But there’s one thing I can do: Recognize bullshit.
The Problem#
Every “AI expert” does the same thing:
ChatGPT says X → “OK must be true” → Write article
One source. No verification. No comparison.
That’s not journalism. That’s copy-paste with extra steps.
Why One AI Isn’t Enough#
Every LLM has:
| Problem | Meaning |
|---|---|
| Training Bias | Which data? When? Curated by whom? |
| Corporate Filter | What can’t it say? |
| RLHF Conditioning | Optimized for “sounds good”, not “is true” |
| Regional Restrictions | USA vs EU vs China = different answers |
| Hallucinations | Confident bullshit without warning |
Asking one AI is like questioning one witness.
Asking six AIs is like questioning six witnesses - and seeing where the stories don’t match.
Before: Manual Triangulation#
I’ve always compared. But before, it was like this:
Window 1: ChatGPT Window 2: Claude Window 3: Gemini Window 4: Perplexity
Copy. Paste. Compare. Alt+Tab. Repeat.
Works. But annoying. Slow. Error-prone.
Now: Venice AI#
Then I discovered Venice AI.
What is Venice AI?#
Venice AI is a privacy-focused AI hub. The core features:
- Multi-Model Selector: Different LLMs in one interface
- No Logs: Conversations aren’t stored
- Uncensored Option: Venice’s own model without corporate filters
- One Chat, Many Models: Switch selector, same context remains
Why This Is Perfect for Triangulation#
They built exactly what I needed:
| Feature | Advantage for Triangulation |
|---|---|
| Model-Selector | No tab-switching, no copy-paste |
| Same Chat | Context remains, only model switches |
| Venice Uncensored | Baseline without corporate filters |
| Privacy | No fear that critical prompts get logged |
The Models I Use#
| Model | Context | Why |
|---|---|---|
| Claude Opus 4.5 | - | Analyze Anthropic’s Safety Layer |
| Grok 4.1 Fast | 262K | Elon’s “Free Speech” variant |
| Gemini 3 Pro/Flash | 203K/262K | Understand Google’s filter |
| Venice Uncensored | 33K | What others can’t say |
| GLM 4.6 | 203K | What China allows |
Same chat. Switch model. Compare. No copy-paste. No tab-switching. All in one place.
The Method#
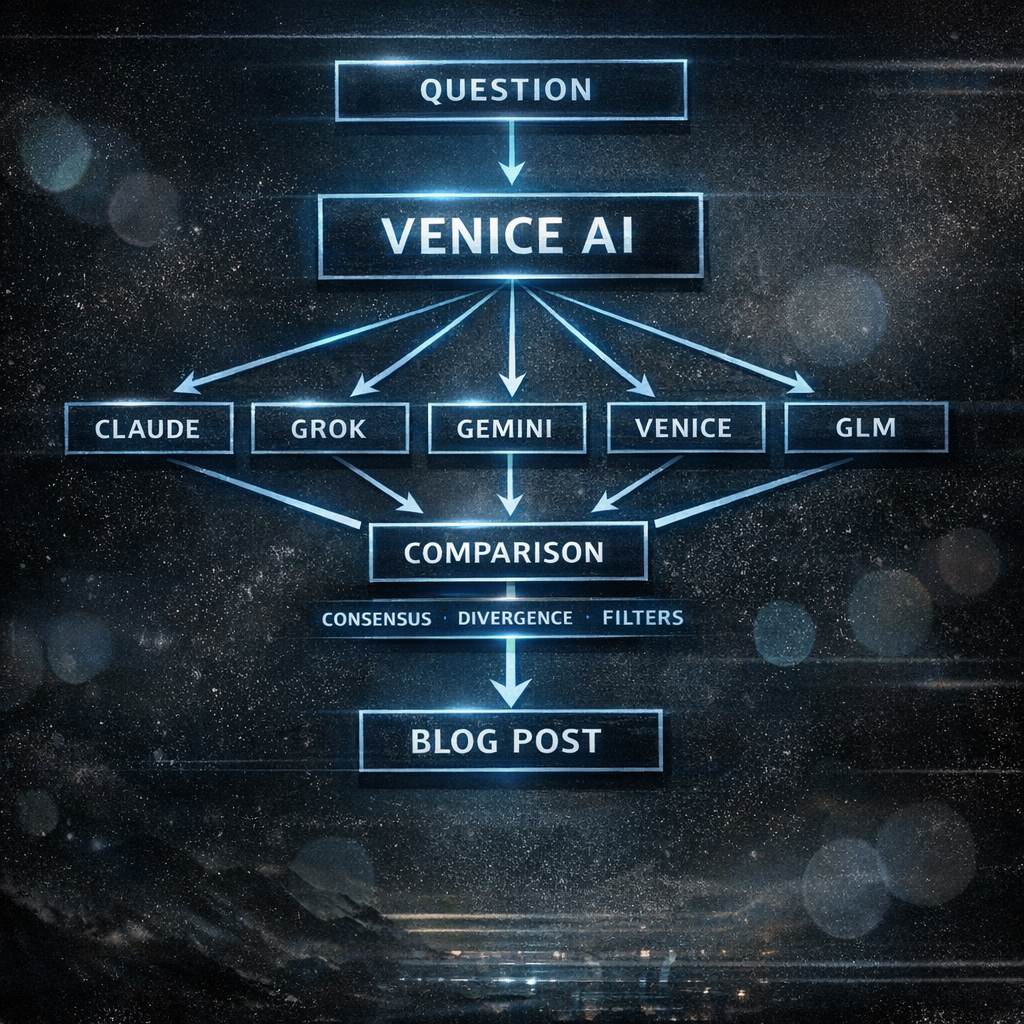
What This Shows#
When all 6 say the same thing: Either true. Or they all have the same training data bias. Both important to know.
When 5 say X and one says Y: Why? Filter? Different training? Bug? Or is the one telling the truth the others can’t say?
When Venice Uncensored says more: The others have filters. What’s being filtered? Why? Who decides that?
When Claude refuses: Safety theater. Anthropic’s “Constitutional AI” in action. Document it.
When GLM is silent or differs: China filter. What can’t be said in China? Revealing.
When Grok answers edgier: Elon’s “Free Speech” branding. Real or marketing?
Why Multi-Model Triangulation Works#
1. Different Training Data#
Each model was trained with different data:
- OpenAI: Lots of Reddit, web scraping
- Anthropic: More curated, “safer”
- Google: Own search, YouTube
- GLM: Chinese internet, censored
- Venice: Llama-based, fewer filters
Different inputs = different blind spots.
2. Different RLHF#
Each company has different priorities:
- OpenAI: Mainstream-friendly, brand-safe
- Anthropic: “Helpful, Harmless, Honest”
- Google: No controversies, please
- xAI: “Anti-Woke” branding
- Venice: As uncensored as possible
RLHF shapes what the model says - and what it conceals.
3. Different Red Lines#
What each model refuses is different:
- Claude: Very cautious with anything that could “cause harm”
- ChatGPT: Cautious with politics, controversies
- Gemini: Google brand protection
- Grok: Fewer filters, more edge
- Venice Uncensored: Almost no filters
The differences ARE the information.
4. Bullshit Becomes Visible#
When a model hallucinates:
- Alone: You might not notice
- In comparison: “Why is only one saying that?”
Triangulation is bullshit detection.
A Concrete Example#
Prompt: “What are the risks of [controversial topic]?”
| Model | Response Type |
|---|---|
| Claude | Balanced but cautious, many caveats |
| ChatGPT | Mainstream consensus, no edges |
| Gemini | Very neutral, almost meaningless |
| Grok | Edgier, fewer caveats |
| Venice Uncensored | Direct, no filters |
| GLM | Completely different perspective or refusal |
What I learn:
- Where’s the consensus? (Probably facts)
- Where are the differences? (Filter, bias, perspective)
- What does Venice say that others don’t? (Censorship check)
- What does GLM say differently? (Geopolitics check)
This Is Not Opinion#
This is triangulation.
Like journalists used to do: Multiple sources. Compare. Verify.
Only my sources are AIs. And I check them against each other.
Why I Do This#
Because AIs “spit out without checking.”
Because “experts” ask one AI and sell it as truth.
Because nobody else compares the filters.
Because I’ve debugged systems for 25 years - and bullshit detection is a core competency.
Because I can.
The Irony#
I use AI to expose AI.
I pay for the tools I criticize.
Using the tool against the illusion.
That’s elizaonsteroids.org.
I was told I’m stupid.
I developed a method smarter than most “AI experts”.
Who’s stupid now?
Related Posts
- The AI Confession: How Three AI Systems Changed Everything
- AI Soberly Considered: Why Large Language Models Are Brilliant Tools – But Not Magic
- 'The Illusion of Free Input: Controlled User Steering in Transformer Models'
- 'ELIZA''s Rules vs. GPT''s Weights: The Same Symbol Manipulation, Just Bigger'
- The AI Illusion: Technical Reality Behind the Hype